

- How Bonfire Ventures Became the #1 Cited Venture Firm in AI Search - June 4, 2026
- Case Study: How We Increased Conversion Rates by 50% for Dutch and Reclaimed AI Visibility - April 14, 2026
- The Top 17 Direct Mail Companies - June 11, 2025
For most businesses, data is essential.
It’s nearly impossible to make key decisions and engender business growth if you’re not ahead of vital information, events, and their details that impact daily business operations.
In essence, you need data. And where can you find most of it, if not all of it?
Search engines. Four of the top 10 most visited websites in the world are search engines. That makes them a treasure trove of data — if you know how to access it.
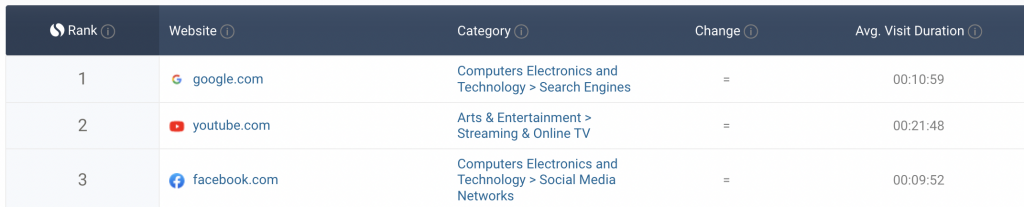
A recent court ruling made web scraping 100% legal, so why not give it a try?
Table of Contents
How Did I Get Into Search Engine Scraping?
In 2020, I started GrowthBar, an AI writing tool that makes it easy for anyone to rank on page one of Google. But unlike other writing tools, GrowthBar is an AI writing tool made for search engine optimization (SEO).

So right from the get-go, we knew we had to scrape search data from Google in order to give our users the information they needed to make content that ranks.
You can see in the image below, GrowthBar surfaces keywords, headlines, images, and more. Where do you think we get that data?
Google!
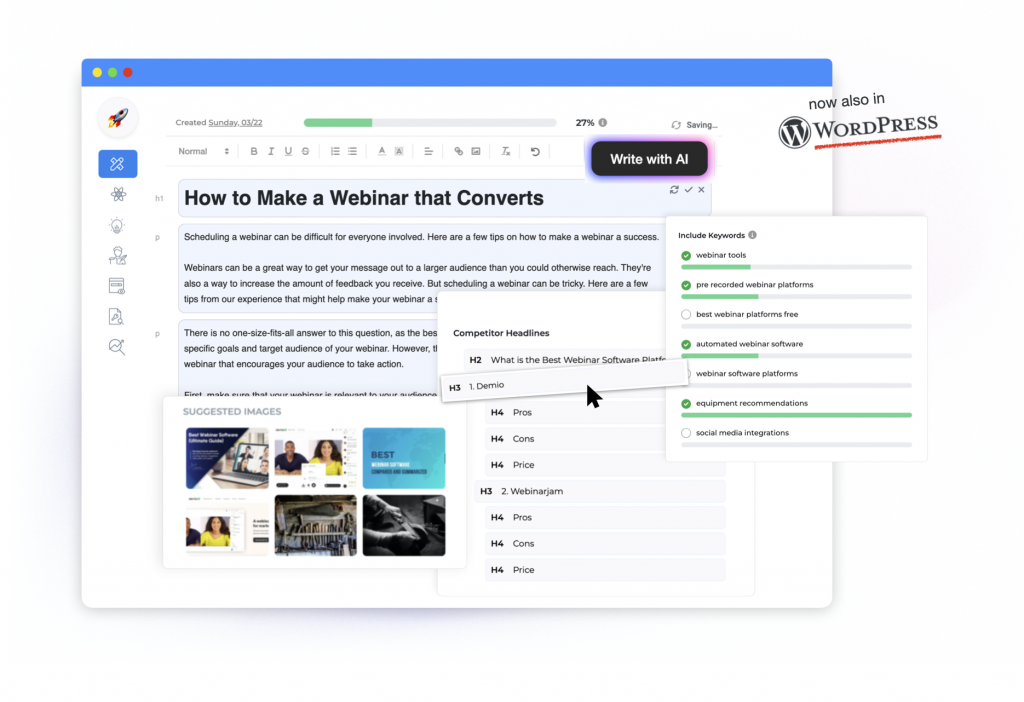
So creating GrowthBar is what sent me on this journey.
Here’s what I learned…
What Is Search Engine Scraping?
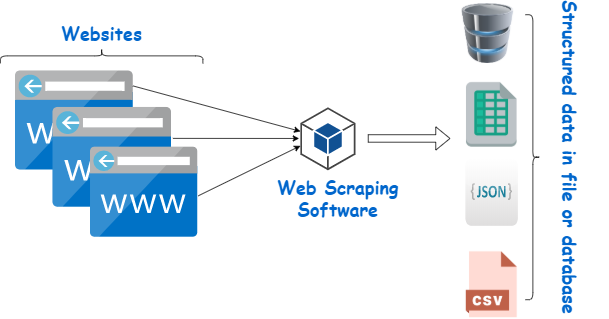
Search engine scraping is the systematic process of obtaining public data from search engines, such as web page links, descriptions, images, and other information.
Search engine scrapers are specialized automated tools that are used to capture publicly available data from search engines. They enable you to collect and return search results for any given query in an organized fashion.
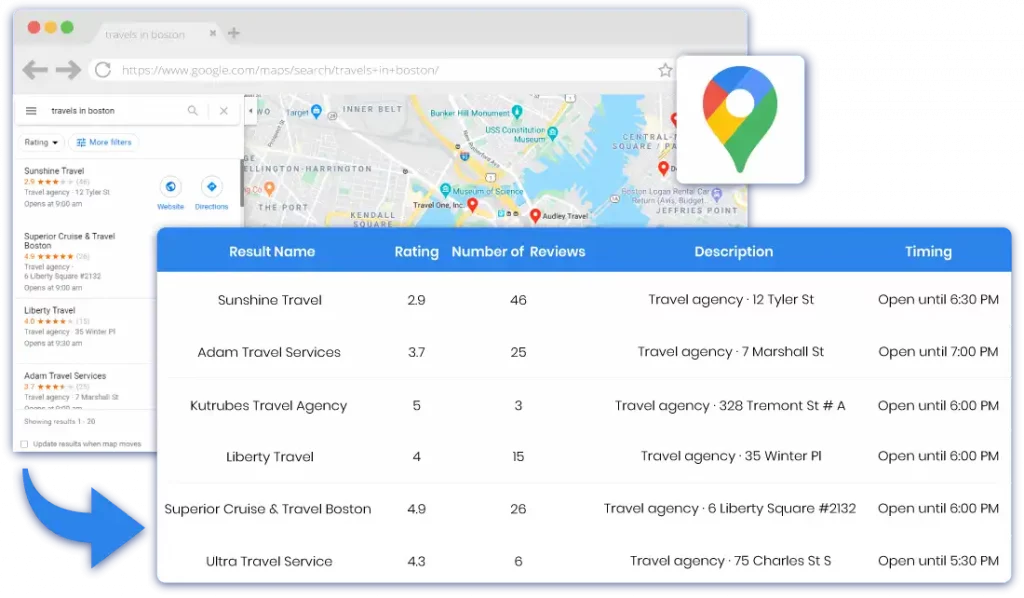
This technique (albeit automated) allows you to collate information from numerous (but distinct) online pages in a matter of seconds or hours. This is faster and far more efficient than visiting all of these web pages by yourself to obtain the information you want, don’t you think?
Plus, if you’re building a SaaS tool, your users probably don’t have days to wait to get the information they’re looking for.
Some web scrapers are designed to gather all the data on a page, while others are designed to retrieve specific data and information.
Moving forward, search engine scraping is the practice of collating information from search engines such as Google using web scraping techniques.
What are Search Engine Scrapers?
Search engine scrapers are automated software that ‘scrape’ pertinent data from a search engine and deliver it to you in a structured format. You’ll probably use a SERP scraper when you wish to programmatically gather data from search results pages.
Quick definition: A SERP (aka search engine results page) is the page that appears on your screen after you enter your search keywords in search engines. Of course, Google is the most popular. However, each search engine’s SERP setup is distinct.
Scraping tools collect data by sending HTTP queries to search engines. Then it analyzes publicly accessible content as HTML files.
Scrapers may perform API queries for particular data, such as specific values or product pricing, which are saved in a database and supplied to browsers via HTTP requests.
It’s a little technical, but it’s actually not too complicated of a process.
Why Do You Need to Perform Search Engine Scraping?
Below are reasons why you might need to opt for search engine scraping:
- Monitoring your competitors: Some people use search engine scrapers to understand what their rivals are up to. Scraping through a competitor’s web pages on search engines may provide you with a wealth of information, such as digital marketing techniques, bestseller items, and even social media activities. It may also help you foresee trends and make decisions, notably in product and service development, giving you a competitive advantage. Famous examples of these include companies that scrape Amazon for pricing information and sell this data to other ecommerce businesses.
- Tracking SEO performance: SEO software tools love scraping search engines. This is perhaps the most prevalent application of search engine scraping. In general, what a good SEO plan depends on for success is data. You need to know the best link-building chances, the most commonly-used keywords, or how your rivals rank well with SEO. SERPs (search engine results pages) are rich with data, such as meta titles, descriptions, keywords, and more. Well-known tools like Semrush and Ahrefs work by scraping search engine data.
- Brand protection: It is not easy building a brand from scratch. Hence you know that threats against your brand’s reputation cannot be taken lightly, and doing that entails increasing your brand protection and security. This is another excellent use case for search engine scraping. Some brands use it to uncover copycats or find competitors using elements of their business (like images or videos) without permission. You know the stock photo sites like Getty are using web scrapers to find bad actors not paying for use of their images!
- Strengthening efforts of digital marketers: Data obtained by search engine scraping enables digital marketers to collate and assess which marketing methods are working just fine and which need to be improved. You may also use search engine scraping to compare your advertising and marketing efforts to your competitors. Content, in particular, is regarded as the primary foundation of modern digital marketing. Search engine scraping may give you important information about current ranking content on a certain query. Understanding higher-ranking blog entries, whether how-to articles or simple guides, may help boost your conversion rates and CTRs.
Is Scraping Search Engines Legal?
As I said, there’s nothing illegal about web scraping. Because search engine results are open to the public, courts have ruled that the information is public domain. Plus, Google does not prosecute scraping.
It is vital to know that web scraping might be legal if done without violating any laws about the source data itself. Before going on a web scraping campaign, ensure you get a little legal advice.
Definitely do not scrape social media sites with personal user information. This type of web scraping has been shot down and prosecuted by companies like Meta and LinkedIn in recent years.

What Happens When You Scrape Popular Search Engines?
If search engines like Bing, Yahoo!, and Google are your targets, then you need to be ready for anything and everything. These search engines know they are being scraped, and as they do not want this (although it is hilarious because they also do it), they have set many obstacles to prevent this. Your scraper must be top-notch to beat these obstacles, and if you cannot build one, you can rent or buy one. Purchased scraping software is, of course, more sophisticated than free ones.
Here are the common approaches these major search engines use in discouraging users:
- Limiting Users: This involves using speed limitations. They also watch out for patterned, regular behavior and term it robotic.
- Blocklisting IP Addresses: If the website identifies a user as a bot, they blocklist its IP address to prevent it from getting access in the future.
These are just some of the ways popular search engines mitigate scraping. If you can create a web scraper that can replicate human behavior as closely as possible, then, by all means, go for it. However, this would require a great deal of technical knowledge, not counting the time involved.
Here are some ways to evade these obstacles:
- Using a rotating proxy to ensure your main IP cannot be tracked and blocklisted.
- Managing your bot’s speed and time to escape the time restrictions on the search engine. Bots are faster than humans, so you have to consider that when designing your bot.
- Captchas and HTML dot parsing are other common methods of escaping search engine limitations.
With all of these, it might be better for you to get a faster and quicker tool for data extraction for your business.
How Google Helps Businesses: Using SERP APIs
Google is undoubtedly the most popular search engine on the planet. Handling more than 80% of search results, Google is the place to go to for knowledge about anything and everything. Effectively, Google’s data is the most comprehensive encyclopedia regarding business.
Millions of businesses devote resources to scrape Google SERPs. With this type of information, they may enhance their products in the following ways:
- Analysis of market trends: When using SERP API for search engine data, they can, with ease, see patterns that can help with targeting their perfect customers. Google’s data reflects client demand, offering enhanced insight into various marketplaces and the products and services that dominate these areas.
- SEO: Because Google ranking practically makes or mars a business, ranking high on search results pages is always a good thing for businesses. As a result, businesses need to develop and use effective SEO strategies for Google to rank their sites high. Getting the keywords from a Google search page is where a SERP API comes in.
With SERP APIs, you can get the keywords that matter in your niche and use them pragmatically in your content. But first, you need to get these keywords.
This is automatic with SERP API – there is no need to monitor the process in any way. Results are delivered in standard HTML or JSON format for easy integration and use. Businesses can focus on getting the results they need without needing to watch out for the blocking measures put in place by search engines.
Conclusion
In today’s fast-paced world, becoming data-driven is an essential approach for modern businesses, whether big or small. Data received through the internet, especially search engines, enables a company to gain highly beneficial information and knowledge about the company, the industry it belongs to, its rivals, its customers, and other aspects.
Data is key to success, and search engine scraping is one of the most excellent strategies for obtaining the data you want.

